

Untertitel sind eine effektive Methode, um die Barrierefreiheit, das Engagement und die Informationsspeicherung während Präsentationen und Live‑Veranstaltungen zu verbessern. Dies, zusammen mit sich ändernden Video‑Nutzungsgewohnheiten im Bereich des Video‑Streamings, hat kürzlich die Einführung von KI‑gestützter Untertitelung bei Live‑Veranstaltungen und Geschäftstreffen beschleunigt.
Aber wenn es darum geht, einen Anbieter für Ihr eigenes Meeting oder Ihre Veranstaltung zu wählen, lautet die am häufigsten gestellte Frage: Wie genau sind automatische Live-Untertitel?
Die kurze Antwort lautet, dass unter idealen Bedingungen automatische Untertitel in gesprochenen Sprachen eine Genauigkeit von bis zu 98 % erreichen können, gemessen am Word Error Rate (WER).
Und ja, es gibt eine lange, etwas komplexere Antwort. In diesem Artikel möchten wir Ihnen einen Überblick darüber geben, wie Genauigkeit gemessen wird, welche Faktoren die Genauigkeit beeinflussen und wie man die Genauigkeit auf ein neues Niveau heben kann.
In diesem Artikel
- Wie automatische Untertitelung funktioniert
- Was gilt als gute Untertitelungsqualität?
- Welche Faktoren beeinflussen die Genauigkeit?
- Messung der Genauigkeit automatischer Untertitelung
- Verstehen der Wortfehlerrate (WER)
- Erhalten Sie unglaublich präzise Untertitel für Ihre Live-Events
Bevor wir in die Zahlen eintauchen, sollten wir einen Schritt zurückgehen und betrachten, wie automatische Untertitel funktionieren.
Wie automatische Untertitelung funktioniert
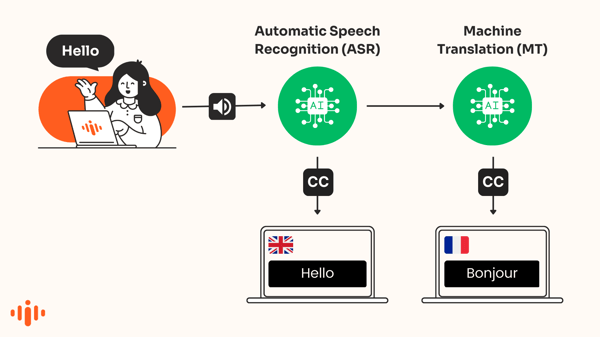
Automatische Untertitel
Automatische Untertitel wandeln Sprache in Text um, der in Echtzeit auf dem Bildschirm in derselben Sprache wie die Rede angezeigt wird. ASR – Automated Speech Recognition – ist eine Form künstlicher Intelligenz, die verwendet wird, um diese Transkripte gesprochener Sätze zu erstellen.
Die Technologie, oft als "Speech-to-Text" bezeichnet, wird verwendet, um automatisch Wörter im Audio zu erkennen und die Stimme in Text zu transkribieren.
KI-übersetzte Untertitel
KI-gestützte Übersetzungs-Engines übersetzen automatisch Untertitel, die in einer anderen Sprache erscheinen. Dies ist auch als maschinell übersetzte Untertitel oder maschinell übersetzte Bildunterschriften bekannt.
Empfohlener Artikel
Warum Sie in Erwägung ziehen sollten, Live-Untertitel zu Ihrer nächsten Veranstaltung hinzuzufügen
In diesem Artikel behandeln wir automatische Untertitel. Wenn Sie etwas über die Genauigkeit von KI‑übersetzten Untertiteln erfahren möchten, prüfen diesen Artikel.
Was gilt als gute Untertitelungsqualität?
Die Federal Communications Commission (FCC) hat 2014 wesentliche Merkmale festgelegt, um zu bestimmen, ob Untertitel "exzellent" sind:
- Genauigkeit -Untertitel müssen den gesprochenen Worten so genau wie möglich entsprechen
- Vollständigkeit - Untertitel laufen vom Anfang bis zum Ende der Übertragung, so vollständig wie möglich.
- Platzierung - Untertitel blockieren keine wichtigen visuellen Inhalte und sind leicht zu lesen.
- Synchronisation - Untertitel richten sich nach der Audiospur aus und erscheinen mit einer lesbaren Geschwindigkeit.
Bild: KI-übersetzte Live-Untertitelung während eines Webinars
Welche Faktoren beeinflussen die Genauigkeit?
Die ausgewählte KI‑Engine
Nicht alle Speech-to-Text-Engines erzeugen identische Ergebnisse. Einige sind im Allgemeinen besser, während andere in bestimmten Sprachen besser sind. Und selbst bei Verwendung derselben Engine können die Ergebnisse stark variieren, abhängig von Akzenten, Geräuschpegeln, Themen usw.
Deshalb benchmarken wir bei Interprefy ständig die besten Engines, um zu bestimmen, welche die genauesten Ergebnisse liefern. Infolgedessen kann Interprefy den Nutzern die beste Lösung für eine bestimmte Sprache bieten, wobei Aspekte wie Latenz und Kosten berücksichtigt werden. Unter idealen Bedingungen haben wir eine konsistente Genauigkeit von bis zu 98% für mehrere Sprachen beobachtet.
Die Audioeingangsqualität
Qualitätseingaben sind für automatisierte Spracherkennungstechnologie erforderlich, um qualitativ hochwertige Ausgaben zu erzeugen. Es ist einfach: Je höher die Qualität und Klarheit von Audio und Stimme, desto besser die Ergebnisse.
- Audioqualität - Ähnlich wie Konferenzdolmetschen, schlechte Audioeingabegeräte, wie eingebaute Computer-Mikrofone, können negative Auswirkungen haben.
- Klare Sprache & Aussprache - Präsentatoren, die laut, gut getaktet und deutlich sprechen, werden in der Regel mit höherer Genauigkeit untertitelt.
- Hintergrundgeräusche - Starkes Grollen, bellende Hunde oder raschelndes Papier, das vom Mikrofon aufgenommen wird, kann die Audioeingangsqualität stark verschlechtern.
- Akzente - Sprecher mit ungewöhnlichen oder starken Akzenten sowie nicht-muttersprachliche Personen stellen für viele Spracherkennungssysteme ein Problem dar.
- Überlappende Sprache - Wenn zwei Personen übereinander reden, wird das System große Schwierigkeiten haben, den richtigen Sprecher korrekt zu erfassen.
Empfohlener Artikel
Wie genau sind Untertitel in Zoom, Teams und Interprefy?
Wie man die Genauigkeit automatischer Untertitel misst
Die gebräuchlichste Kennzahl zur Messung der ASR-Genauigkeit ist die Wortfehlerrate (WER), die das tatsächliche Transkript des Sprechers mit dem Ergebnis der ASR-Ausgabe vergleicht.
Zum Beispiel, wenn 4 von 100 Wörtern falsch sind, beträgt die Genauigkeit 96%.
Verstehen der Wortfehlerrate (WER)
WER bestimmt die kürzeste Distanz zwischen einem von einem Spracherkennungssystem erzeugten Transkripttext und einem Referenztranskript, das von einem Menschen (der Ground Truth) erstellt wurde.
WER richtet korrekt identifizierte Wortsequenzen auf Wortebene aus, bevor die Gesamtzahl der Korrekturen (Ersetzungen, Löschungen und Einfügungen) berechnet wird, die erforderlich sind, um Referenz- und Transkripttexte vollständig auszurichten. Der WER wird dann als Verhältnis der benötigten Anpassungen zur Gesamtzahl der Wörter im Referenztext berechnet. Ein niedrigerer WER weist im Allgemeinen auf ein genaueres Spracherkennungssystem hin.
Beispiel für Wortfehlerrate: 91,7 % Genauigkeit
Nehmen wir ein Beispiel für eine Wortfehlerrate von 8,3 % – bzw. 91,7 % Genauigkeit und vergleichen die Unterschiede zwischen dem Originaltranskript der Rede und den von ASR erstellten Untertiteln:
| Originales Transkript: | ASR-Untertitel-Ausgabe: |
| Zum Beispiel, ich tue mag nur sehr begrenzte Nutzung von dem Grundlagen bereitgestellt Ich würde gerne einen bestimmten Punkt genauer ausführen, ich fürchte, dass ich rufe auf einzelne Landesparlamente, das Abkommen zu ratifizieren, erst nachdem die Rolle des Europäischen Gerichtshofs geklärt wurde, könnte sehr nachteilige Auswirkungen haben. | Zum Beispiel, ich auch würde wie nur sehr begrenzte Nutzung der Ausnahmen bereitgestellt, ich würde gerne einen bestimmten Punkt genauer ausführen, ich befürchte, dass die Aufruf an einzelne Landesparlamente, das Abkommen zu ratifizieren, erst nachdem die Rolle des Europäischen Gerichtshofs geklärt wurde, sehr nachteilige Auswirkungen haben könnte. |
In diesem Beispiel haben die Untertitel ein Wort verpasst und vier Wörter ersetzt:
- Messwerte: {'matches': 55, 'deletions': 1, 'insertions': 0, 'substitutions': 4}
- Ersetzungen: [('zu', 'machen'), ('verwenden', 'verwendet'), ('Ausnahmen', 'Wesentliches'), ('die', 'ich')]
- Löschungen: ['would']
Die Berechnung der Wortfehlerrate lautet daher:
WER = (Löschungen + Ersetzungen + Einfügungen) / (Löschungen + Ersetzungen + Übereinstimmungen) = (1 + 4 + 0) / (1 + 4 + 55) = 0.083
WER übersieht die Art der Fehler
Im obigen Beispiel sind nicht alle Fehler gleich stark wirksam.
Die WER-Messung kann irreführend sein, weil sie uns nicht mitteilt, wie relevant/wichtig ein bestimmter Fehler ist. Einfache Fehler, wie die alternative Schreibweise desselben Wortes (movable/moveable), werden vom Leser oft nicht als Fehler angesehen, während eine Substitution (exemptions/essentials) stärker wirken kann.
WER‑Zahlen, insbesondere bei hochpräzisen Spracherkennungssystemen, können irreführend sein und entsprechen nicht immer den menschlichen Wahrnehmungen von Richtigkeit. Für Menschen sind Unterschiede in den Genauigkeitsstufen zwischen 90 % und 99 % oft schwer zu unterscheiden.
Wahrgenommene Wortfehlerrate
Interprefy hat eine proprietäre und sprachspezifische ASR-Fehlermetrik namens Perceived WER entwickelt. Diese Metrik zählt nur Fehler, die das menschliche Verständnis der Sprache beeinträchtigen, und nicht alle Fehler. Wahrgenommene Fehler liegen in der Regel unter dem WER, manchmal sogar um bis zu 50 %. Ein wahrgenommener WER von 5-8 % ist für den Benutzer normalerweise kaum bemerkbar.
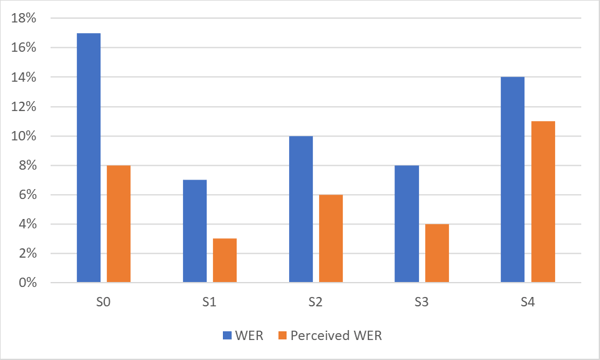
Das untenstehende Diagramm zeigt den Unterschied zwischen WER und wahrgenommenem WER für ein hochpräzises ASR‑System. Beachten Sie den Leistungsunterschied für verschiedene Datensätze (S0‑S4) derselben Sprache.
Wie in der Grafik gezeigt, ist das von Menschen wahrgenommene WER oft deutlich besser als das statistische WER.
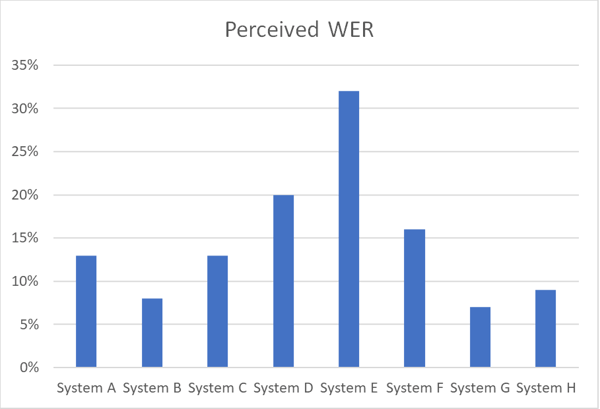
Das untenstehende Diagramm veranschaulicht die Genauigkeitsunterschiede zwischen verschiedenen ASR‑Systemen, die denselben Sprachdatensatz in einer bestimmten Sprache unter Verwendung des wahrgenommenen WER bearbeiten.
Erhalten Sie unglaublich präzise Untertitel für Ihre Live-Events
Wir haben eine Genauigkeit von 97 % für unsere automatischen Untertitel gesehen, dank der Kombination unserer einzigartigen technischen Lösung und der Sorgfalt, die wir für unsere Kunden aufbringen. Alexander Davydov, Leiter der KI‑Lieferung bei Interprefy
Wenn Sie' nach hochpräzisen automatischen Untertiteln während einer Veranstaltung suchen, gibt es drei wichtige Punkte, die Sie berücksichtigen sollten:
Verwenden Sie eine erstklassige Lösung
Statt irgendeine vorgefertigte Engine zu wählen, die alle Sprachen abdeckt, wählen Sie einen Anbieter, der für jede Sprache in Ihrer Veranstaltung die beste verfügbare Engine nutzt.
Möchten Sie verstehen, was die beste Engine Ihnen bieten kann? Lesen Sie unseren Artikel: Die Zukunft der Live-Untertitel: Wie Interprefy KI die Barrierefreiheit ermöglicht
Optimieren Sie die Engine
Wählen Sie einen Anbieter, der die KI mit einem maßgeschneiderten Wörterbuch ergänzen kann, um sicherzustellen, dass Markennamen, ungewöhnliche Namen und Akronyme angemessen erfasst werden.
Stellen Sie eine hochwertige Audioeingabe sicher
Wenn die Audioeingabe schlecht ist, kann das ASR-System die Ausgabequalität nicht erreichen. Stellen Sie sicher, dass die Sprache laut und deutlich erfasst werden kann.


 Weitere Download-Links
Weitere Download-Links



